GeForce RTX 40 系列 GPU 正式亮相後,NVIDIA 進一步解釋 Ada Lovelace 架構的特性。
Ada Lovelace 核心架構

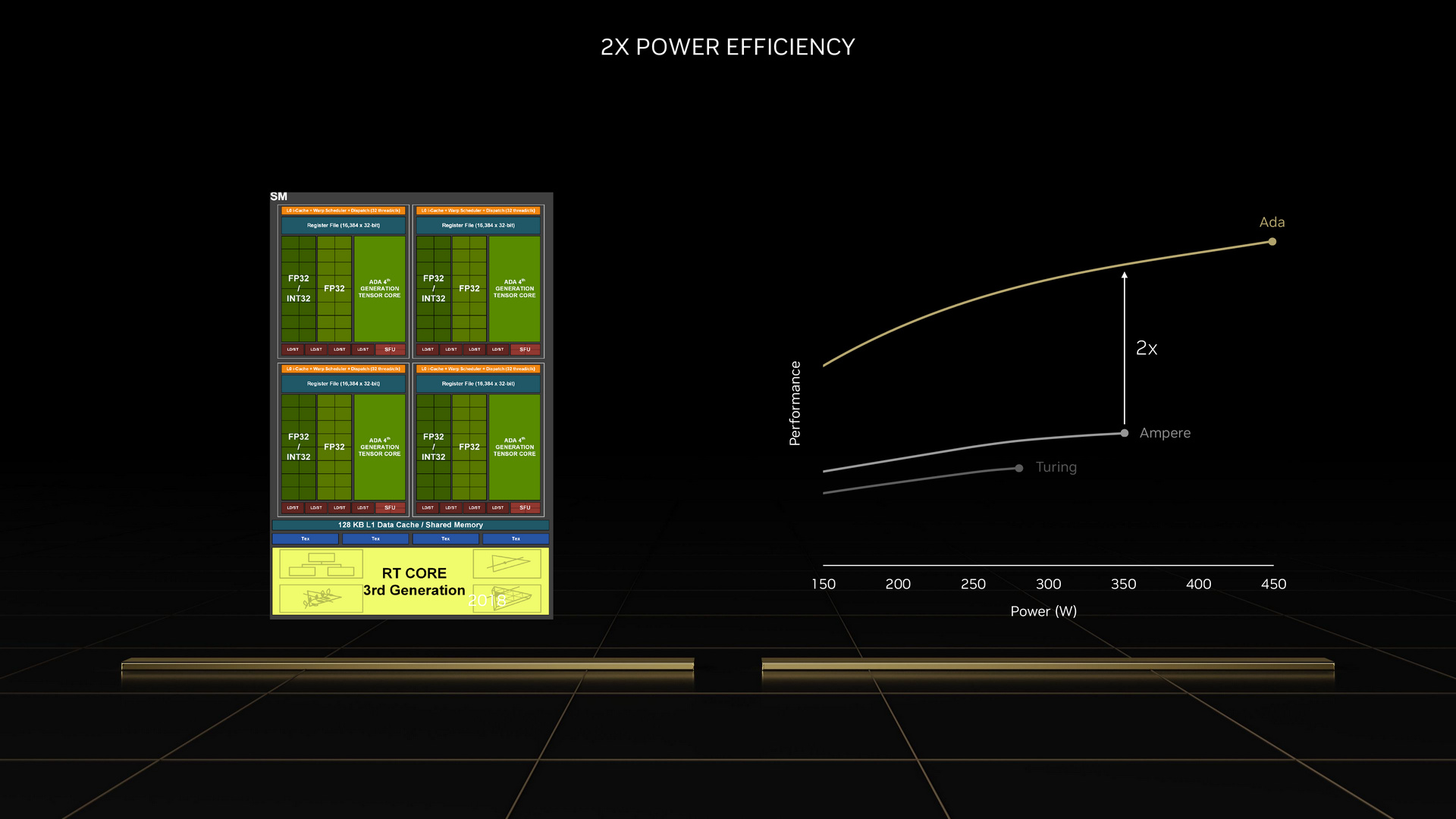
Ada Lovelace 架構的基礎其實很類似前一代的 Ampere 架構,同樣以 SM (Streaming Multiprocessor) 為構成單位,每組 SM 內含 128 個 CUDA Core、1 個 RT Core 和 4 個 Tensor Core。
這 128 個 CUDA Core 和 Ampere 架構一樣,其中一半專責處理 FP32(32 位元浮點數,又稱單精度浮點數)運算,另一半則可依需求,在 INT32(32 位整數)運算和 FP32 運算之間動態切換。
根據 NVIDIA 提供的資料,完整的 Ada Lovelace 架構 AD102 晶片擁有 144 組 SM,這包含多達 18432 個 CUDA Core、144 個第 3 代 RT Core 和 576 個第 4 代 Tensor Core,並且配倍 2 個可處理 AV1 編碼的第 8 代 NVENC 編碼器,整體規模比前代大了不少。
另外在台積電 4nm(TSMC N4)製程的加持下,AD102 晶片的電晶體數量來到 763 億個,且 Boost 時脈可達 2.5 GHz。在同樣功耗下,性能表現可達 Ampere 架構的 2 倍。而且相較於 Ampere 架構大約在 350W 左右就達到效能頂點,Ada Lovelace 架構可一路增加至 450W,還能維持有效的效能成長。
除了規模擴大和時脈提升,Ada Lovelace 架構還有幾項創新功能。
著色器執行重新排序(Shader Excution Reordering, SER)
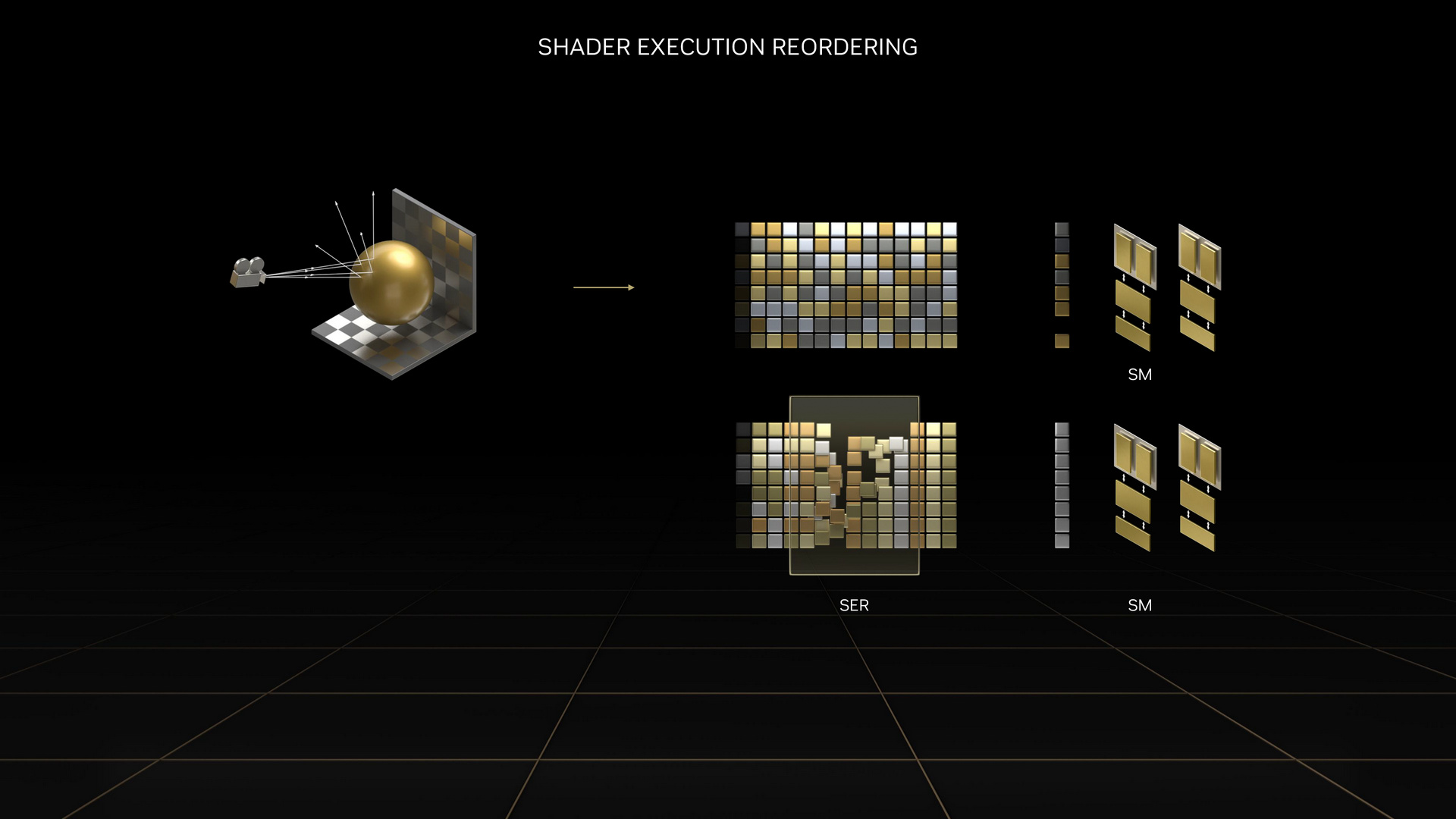
GPU 以平行處理能力著稱,但程式發出的指令請求並不一定同時送來。再者,遇到光線追蹤的工作負載時,因為有著來自各種方向的光線在不同接觸表面上反彈,導致 GPU 需要因應不同的執行緒來處理不同的著色器,因此是出了名的難以平行處理,效率也相當低下。
透過著色器執行重新排序,把同類型的指令即時編排在一起,再同時發送給 GPU 進行處理,進而提高 GPU 的資源效率,這可讓光線追蹤的效能提升至 2 ~ 3 倍,整體遊戲效能也可提升 25%。
Displaced Micro-Mashes
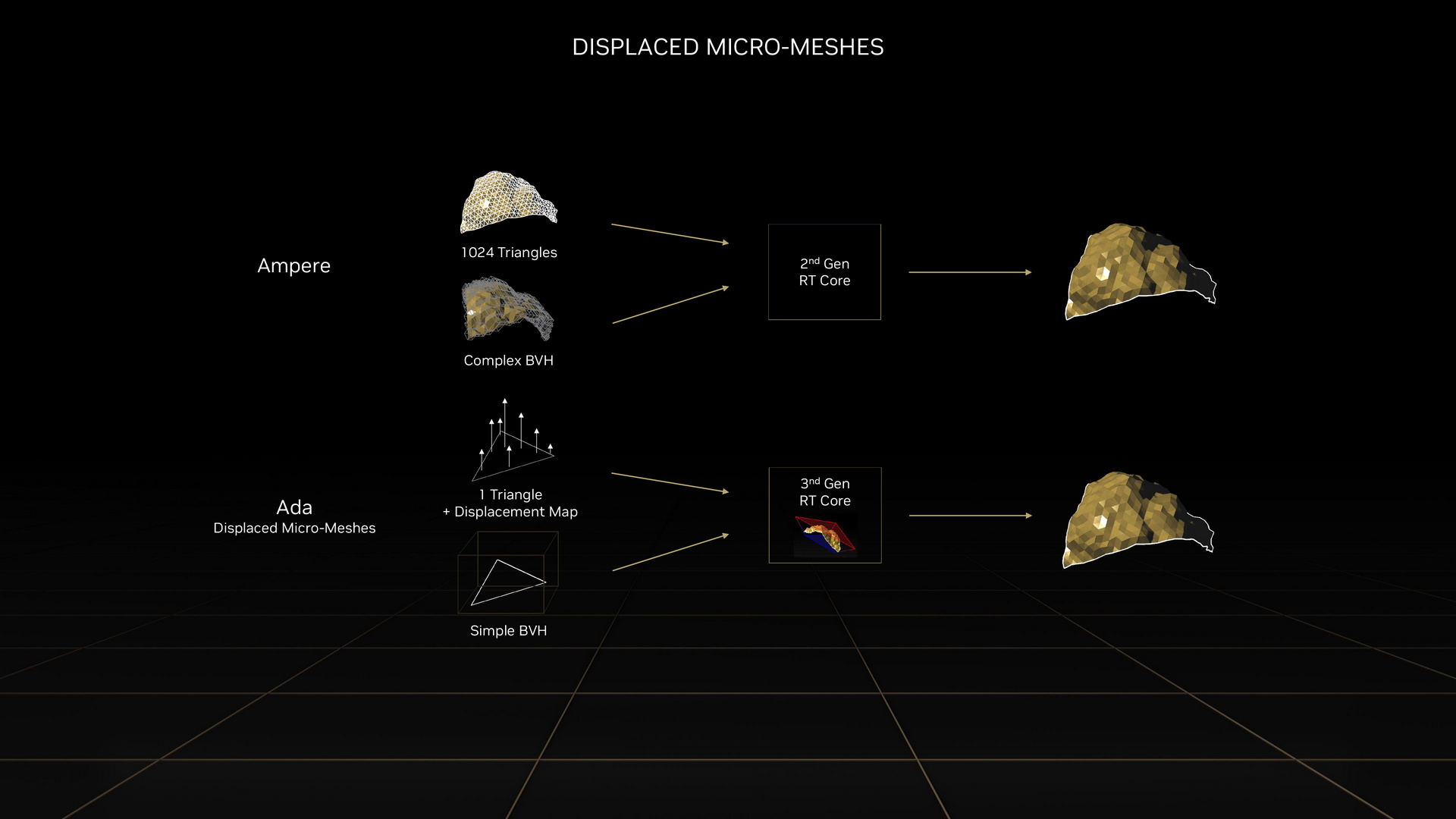

Displaced Micro-Mashes 運用曲面細分(Tessellation)的手法,不需要完整的三維空間座標頂點資料,只需要在大塊的三角形做完簡單的 BVH (Bounding volume hierarchy),再透過置換貼圖(Displacement Mapping)產生大量多邊形,這有點類似圖片壓縮/解壓縮的概念。
NVIDIA 表示,Displaced Micro-Mashes 可提升 BVH 速度達 10 倍,VRAM 占用率可減少到 20 分之 1。
Opacity Micro-Maps
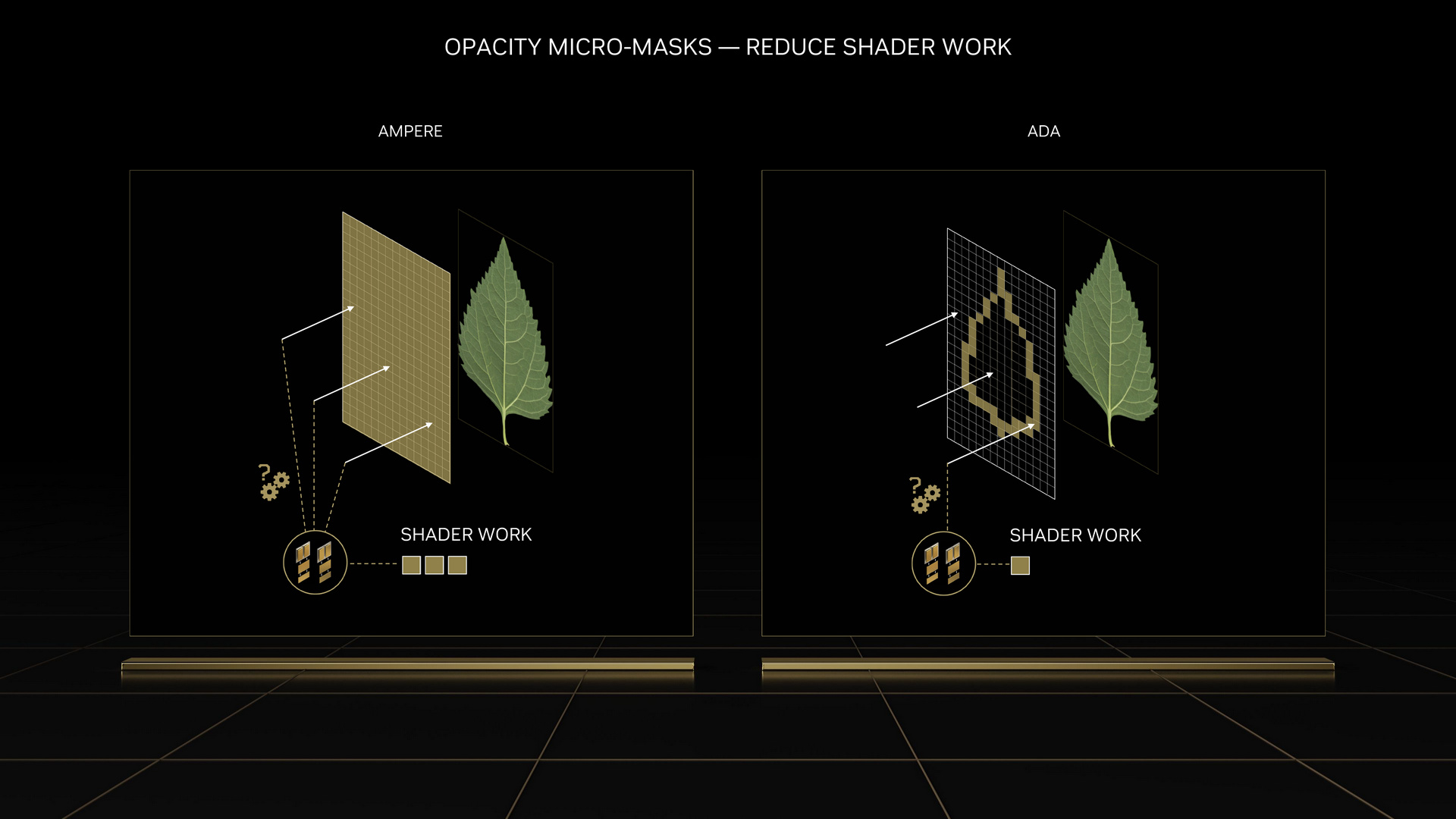
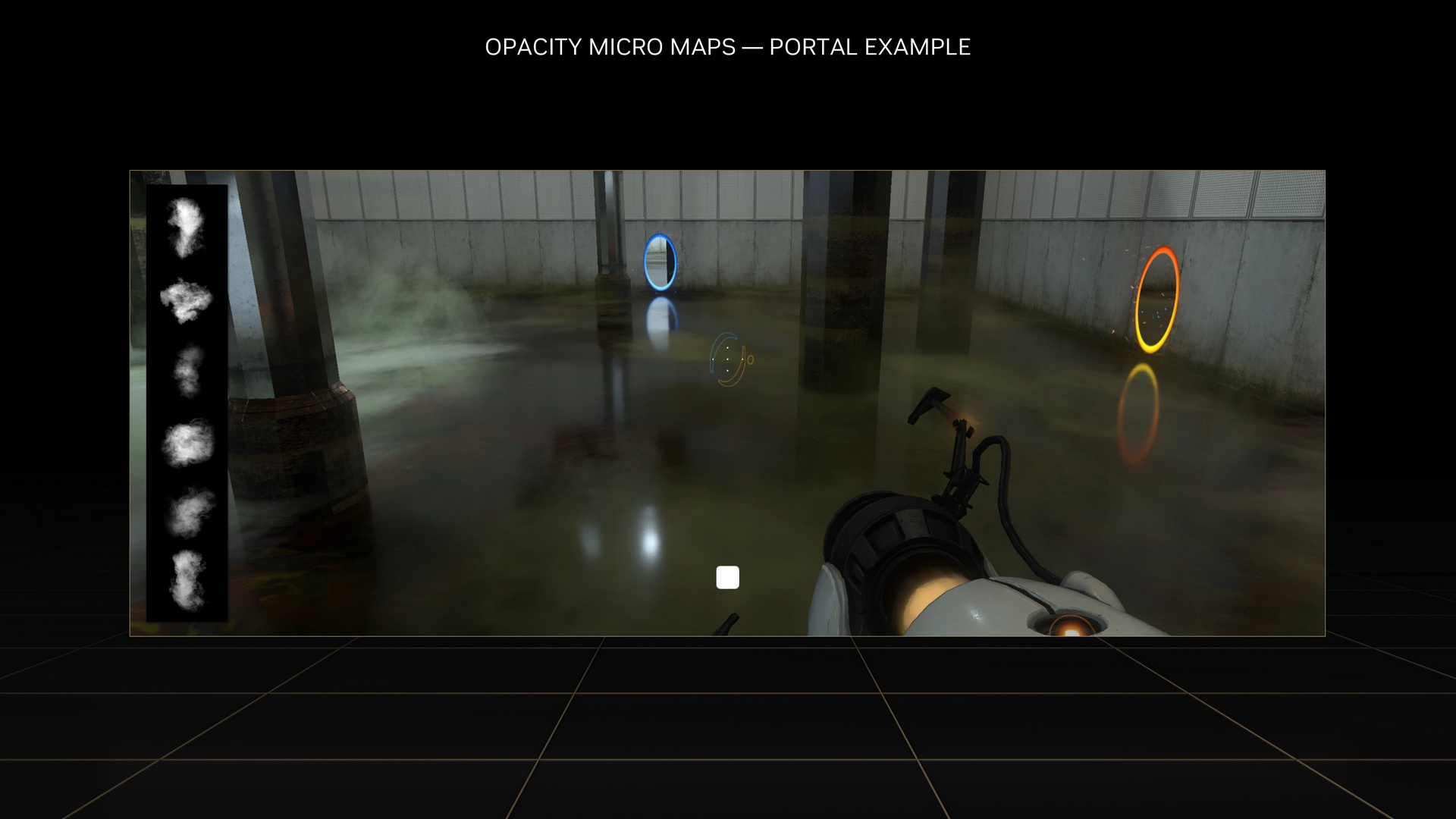
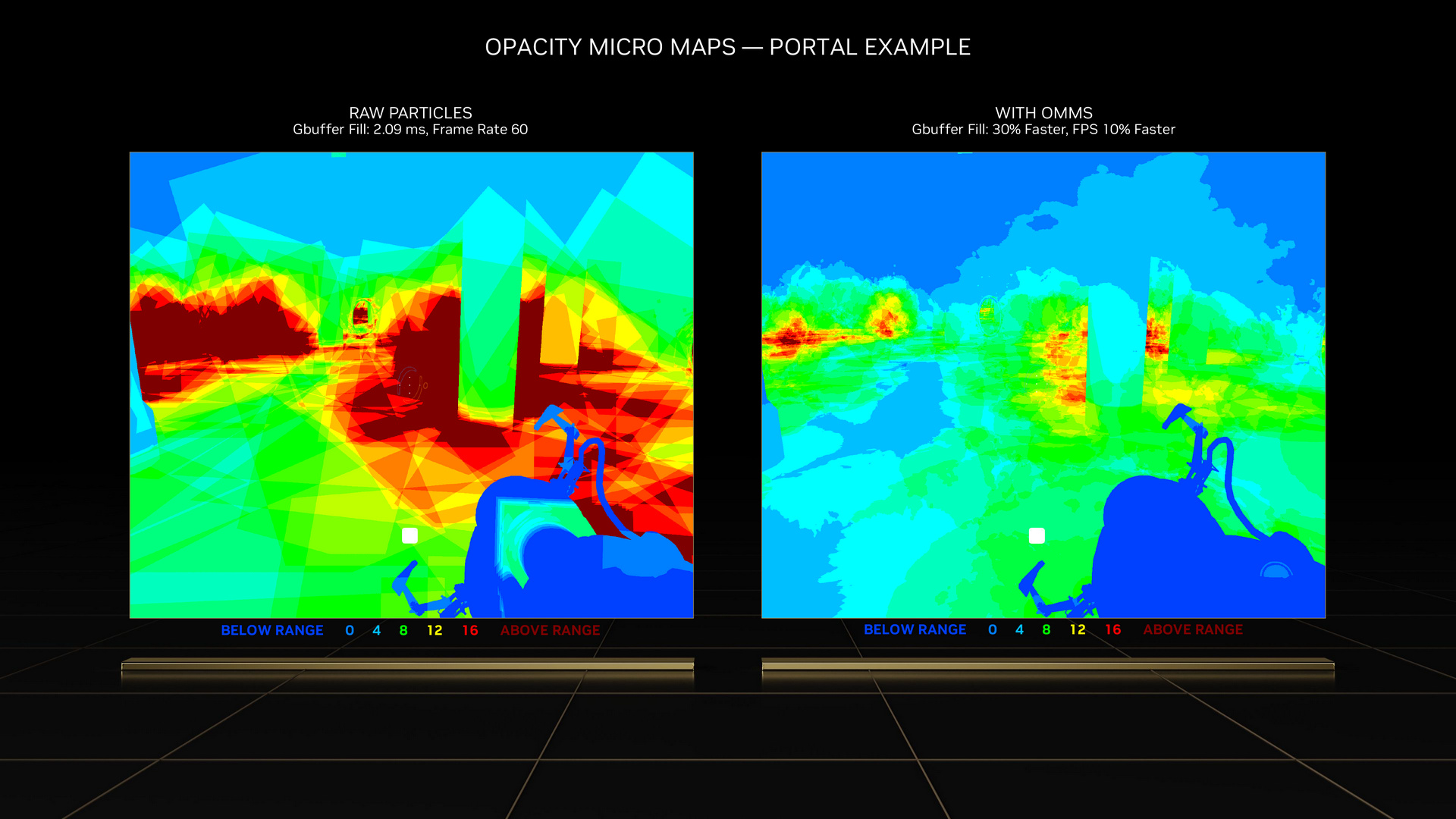
Opacity Micro-Maps 則是在第 3 代 RT Core 新增半透明的定義。以往 Ampere 架構遇到像是樹葉間隙或霧氣等複雜的場景,會把工作丟回 Streaming Multiprocessor 處理,但效率低下。現在 Ada Lovelace 架構這層定義後,就能有效運用第 3 代 RT Core 加速處理。
DLSS 3
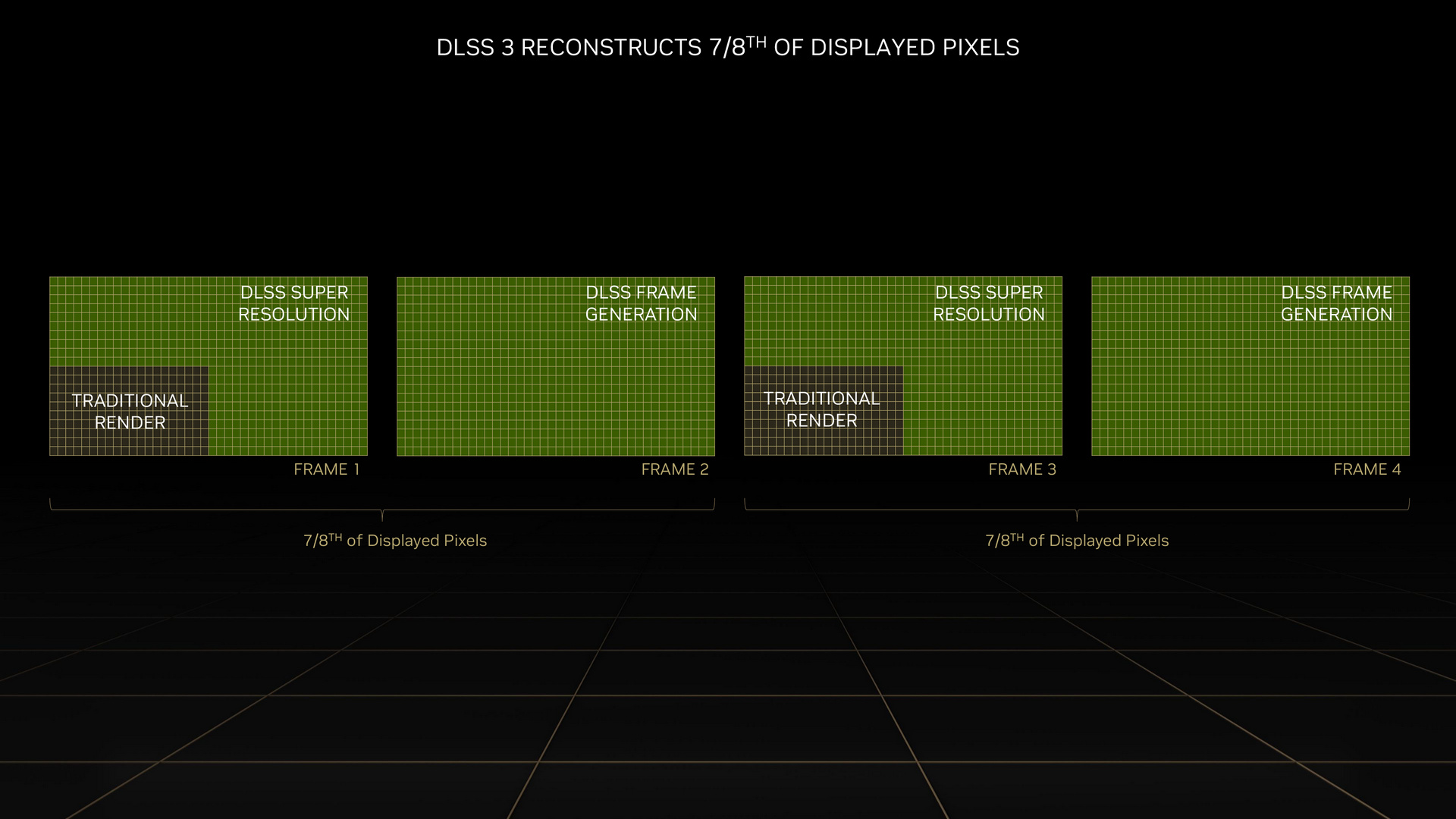

前日的報導已大致講明 DLSS 3 的原理特性,這邊再稍微補充幾點。
與過往 DLSS 2 以前相比,DLSS 3 新增的特色機制就是運用類似「內插補幀」的手法,在原生兩張畫格之間,產生新的畫格。而原有的 DLSS 機制也可在較低的原生解析度,以 Super Resolution 的方式擴增成 4 倍(長寬各 2 倍相乘)解析度像素。
因此,在這兩種機制的同時作用下,DLSS 3 總共可運用傳統原生渲染顯示的像素,產生額外 7 倍的像素內容。這代表執行 DLSS 3 時,其中 8 分之 7 的像素資料是透過 AI 生成的。


從表格中可以看到,DLSS 3 包含 GeForce GTX 900 系列以後就能支援的 NVIDIA Reflex 技術、GeForce RTX 20 系列開始支援的 DLSS Super Resolution 技術,以及 GeForce RTX 40 系列獨有的 DLSS Frame Generation 技術。
對於遊戲開發者來說,DLSS 2 要升級到 DLSS 3 其實相當簡單,引擎資料只要多提供 Reflex Marker 即可,這也可促進更已有 DLSS 2 的 AAA 遊戲加速導入 NVIDIA Reflex 低延遲技術。
總結

在以上幾種創新技術和規模擴大的加持下,Ada Lovelace 架構 GPU 才有能力打出相較於前代 2 ~ 4 倍的效能表現。欲知更多有關 GeForce RTX 40 系列 GPU 的效能表現,敬請鎖定我們的追蹤與評測報導。




![[復仇! ] East Live Collaboration的“ZONe ENERGY REVENGE”將從“ZONe ENERGY”發布!](https://i0.wp.com/saiganak.com/wp-content/uploads/2022/12/zone-energy-revenge-release-00.jpg?resize=266,160)
