
幾天前 NVIDIA 正式向全世界公開 GeForce RTX 30 系列 GPU 時,宣稱效能達前代產品的兩倍強度,甚至讓市面上出現不少前代產品的拋售潮。但大家一定非常好奇新登場的 Ampere 架構究竟運用哪些設計讓性能大幅提升,還有 8K 遊戲是否真的能順暢運行,請看以下 NVIDIA 全新 Ampere 架構的技術解析。
Ampere 核心架構


我們熟知的第一代 RTX GPU 的 Turing 架構由多組 SM(Streaming Multiprocessor)組成,內含 CUDA Core、RT Core、Tensor Core 等 3 總運算核心以及 L1 快取記憶體,而 Ampere 的構造也相當類似。
首先看到 CUDA Core(這次又稱 Shader Core,著色核心),Turing 架構的 SM 將 CUDA Core 分做兩區塊,分線同步進行 FP32(32 位元浮點數,又稱單精度浮點數)和 INT32(32 位整數)運算。
然而到了 Ampere 架構,原本負責整數運算的區塊則改為可依據需求,動態切換為浮點運算(驅動即可判斷),這就是為何浮點運算能力最高可達前代 2 倍,也是現在所見 CUDA Core 數量是先前傳聞 2 倍數字的主要原因。此外,L1 快取則是容量增加 33%,且頻寬和快取區塊都達到前代 2 倍,都有助於更大的運算量。
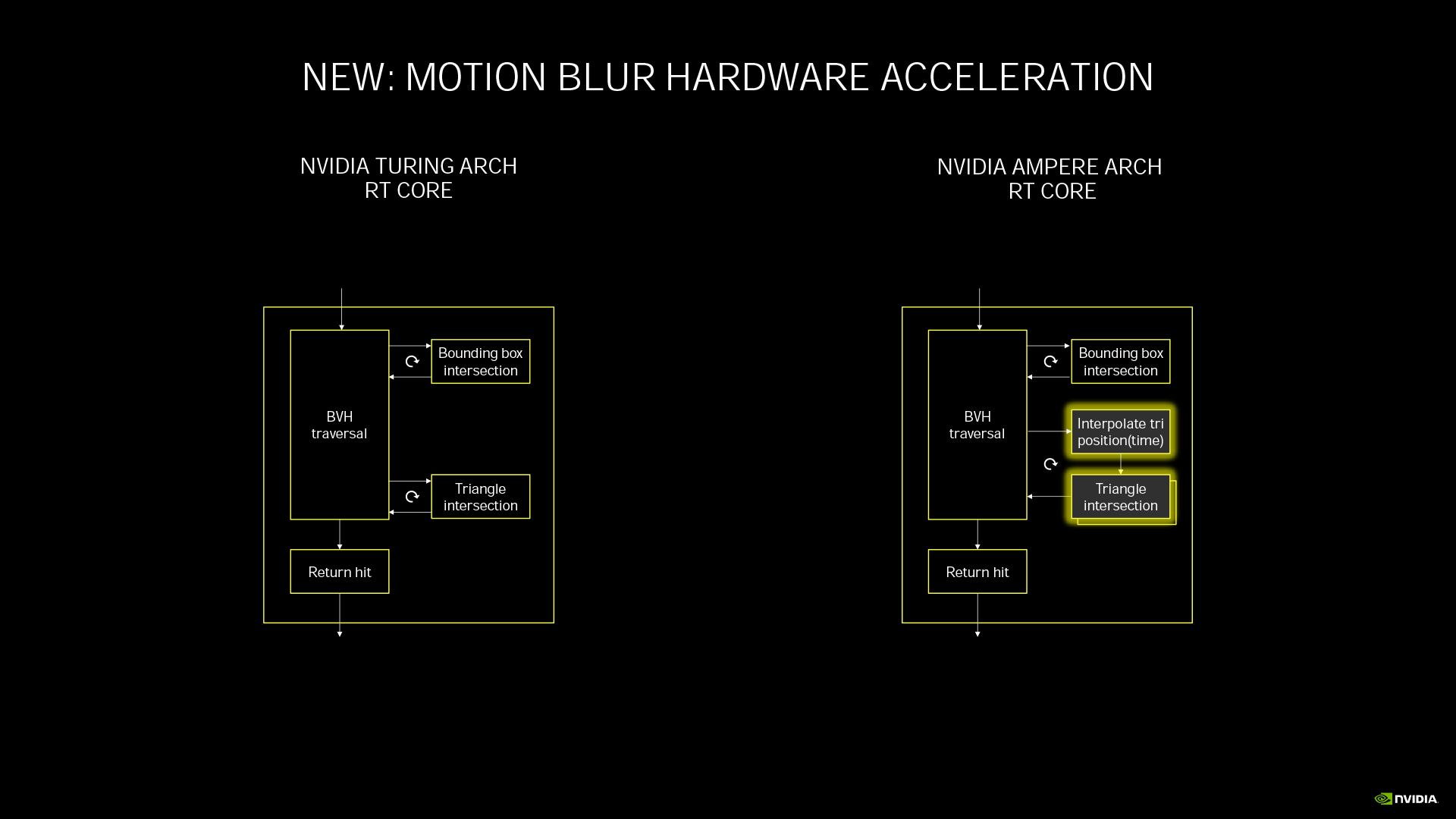
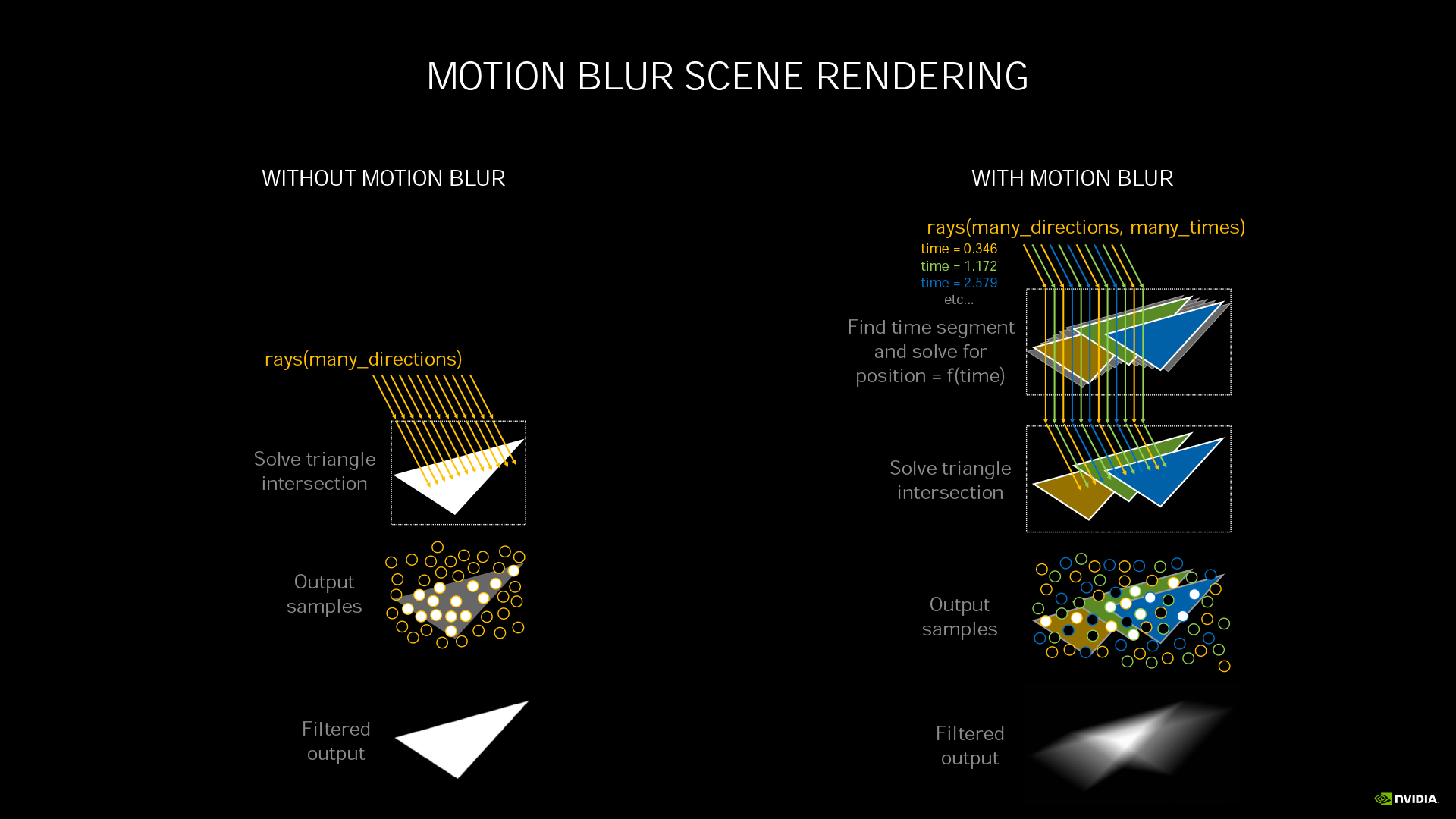
RT Core 在 Ampere 架構進化成第二代 ,主要強化了動態模糊運算。以往的動態模糊是套用濾鏡效果,但呈現的畫面較不真實。光線追蹤的動態模糊則會去真實計算該物件在一個時間區間內的所在位置變動狀態與光線的互動效果,負擔非常大。
第二代 RT Core 可在光線與物件互動的運算過程中,同步進行物件定位運算,整體動態模糊運算速率可達 Turing 架構第一代 RT Core 的 8 倍。
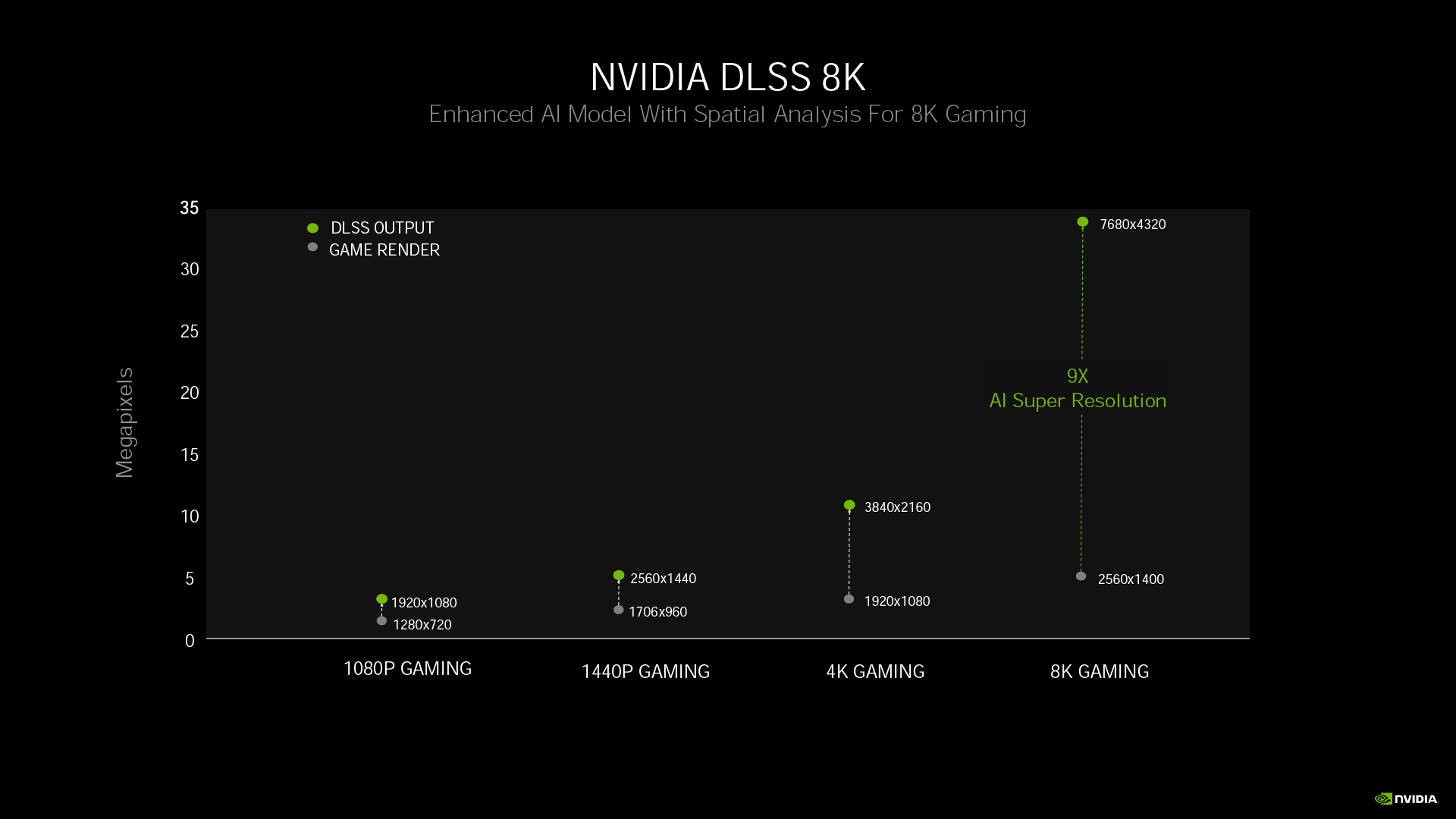
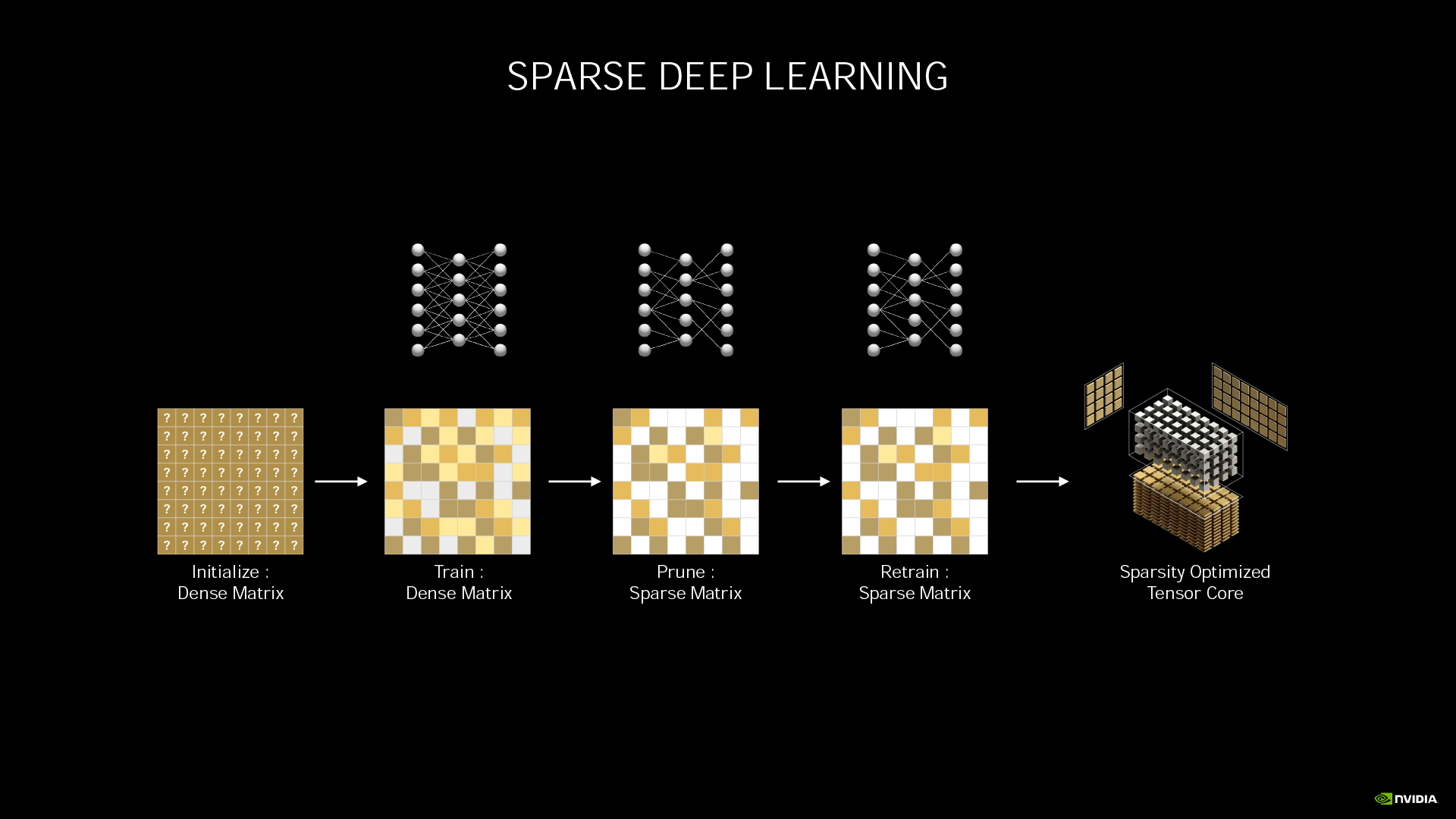
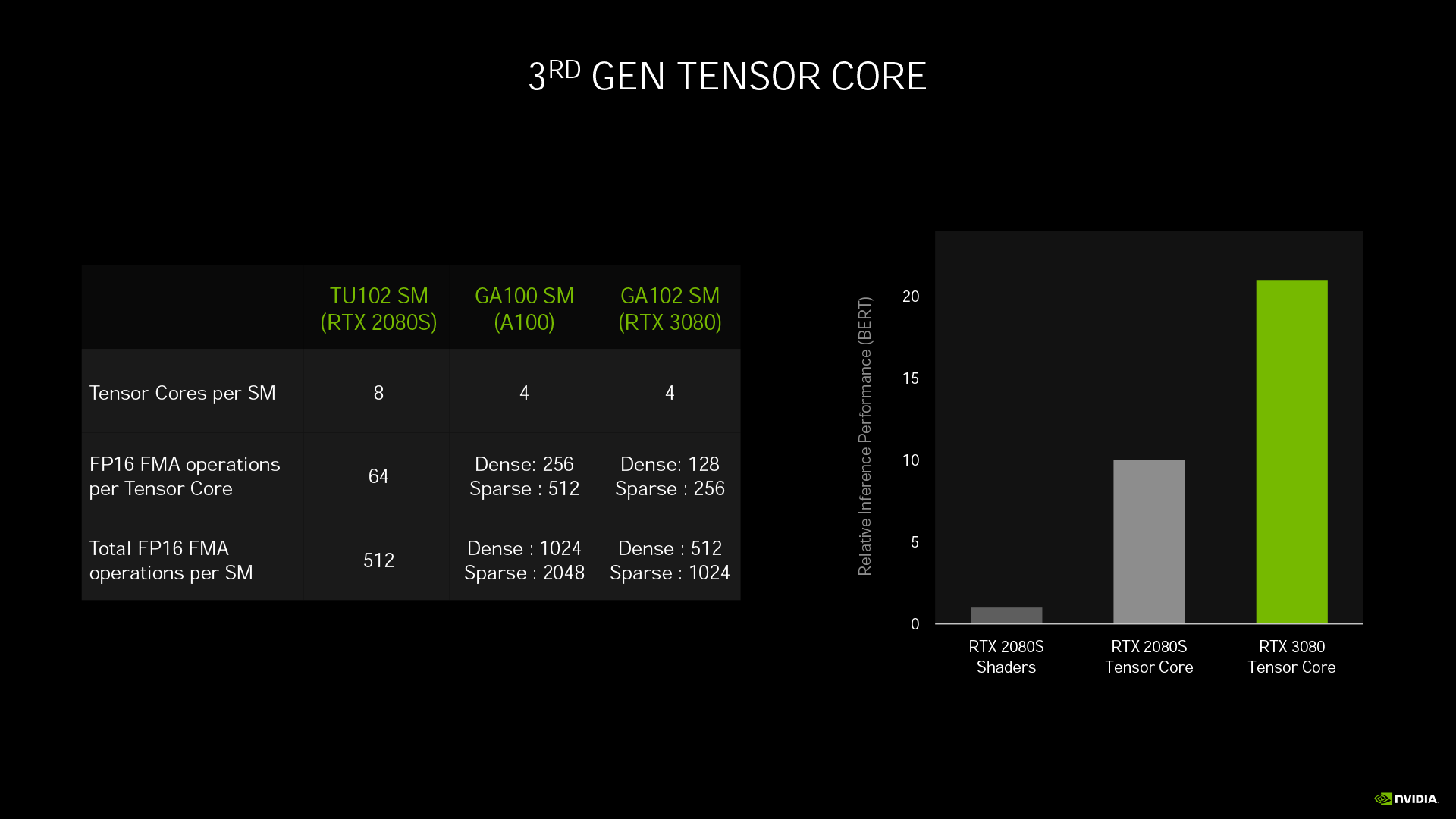
Tensor Core 在 Ampere 架構進化至第三代,運用全新的特殊編碼,將原本密集矩陣的資料轉為稀疏矩陣,再有效分配至 Tensor Core。這讓 Ampere 架構第三代 Tensor Core 每核心運算效率可達 Turing 架構第二代 Tensor Core 的 2 倍,所以 DLSS 提高解析度的效能表現更好,只需要著色核心渲染出 WQHD 解析度的畫面,透過 DLSS 搭配全新的 AI 模型,即可輕鬆擴展至 8K 解析度。

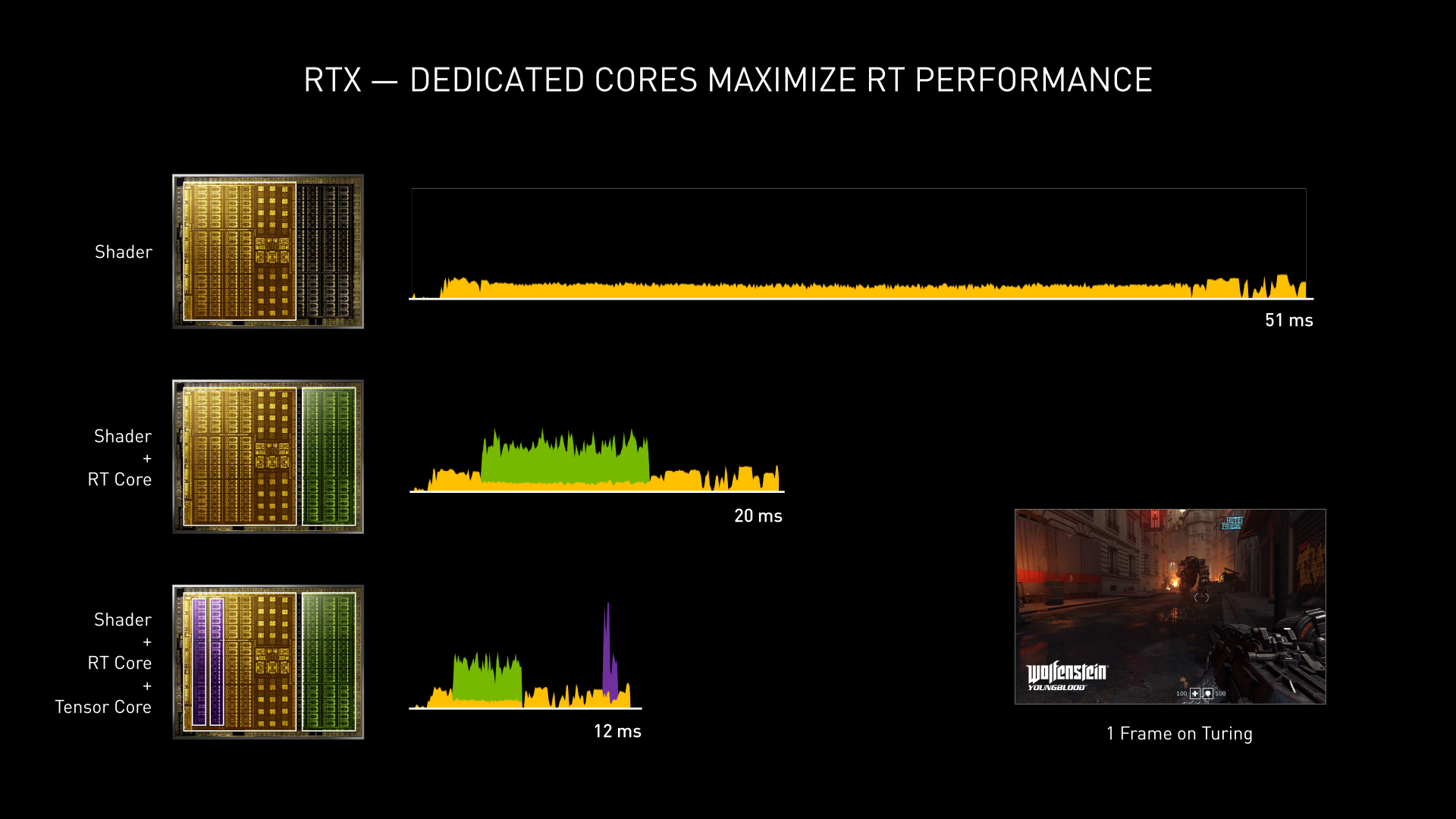
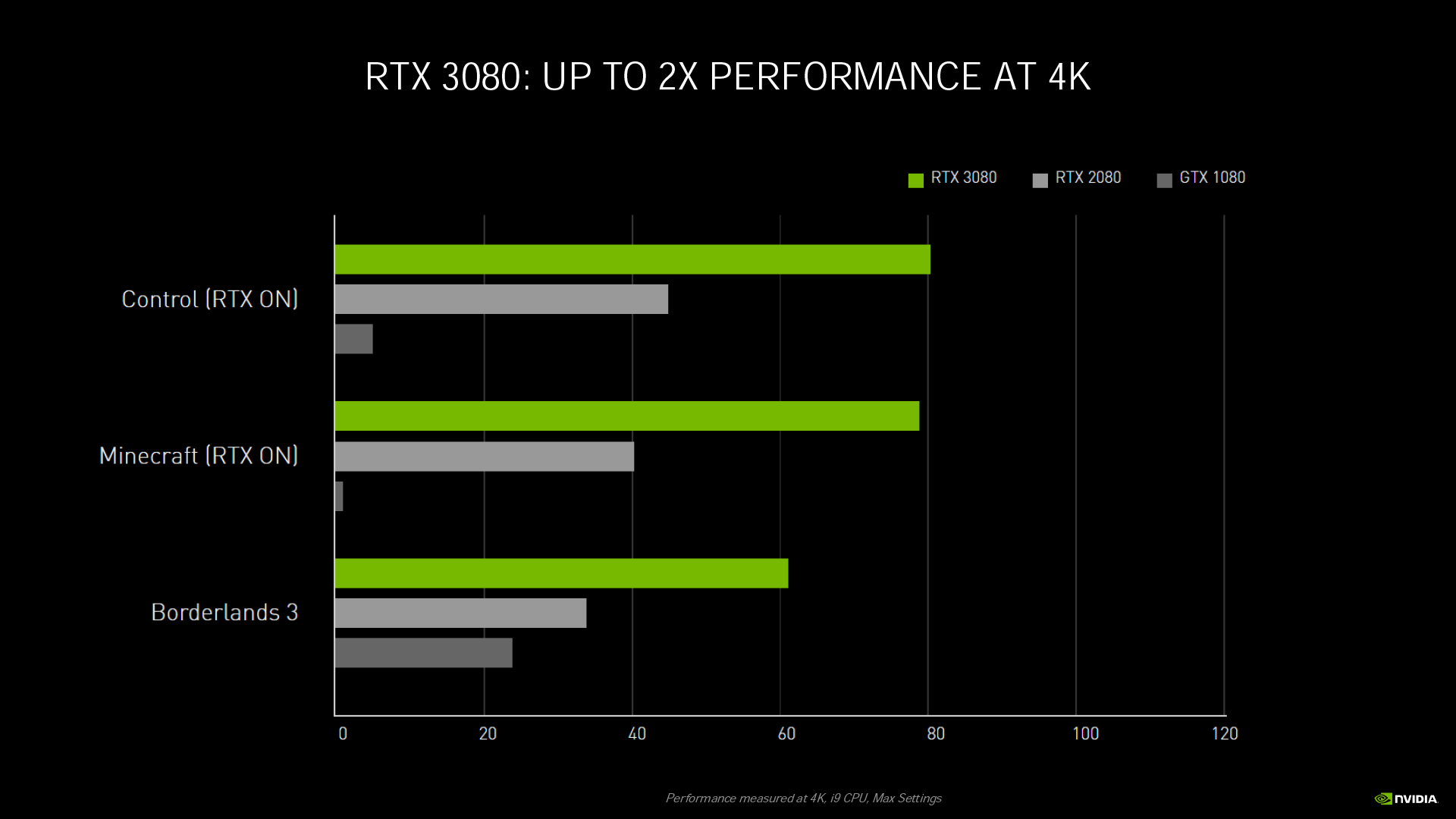
最後,相較於 Turing 架構在著色運算時,光線追蹤和深度學習運算只能依序處理,Ampere 架構可讓著色、光線追蹤、深度學習三種運算同步進行,大幅提高運算效率,這就是 GeForce RTX 3080 可達到 2 倍 RTX 2080 效能的原因。
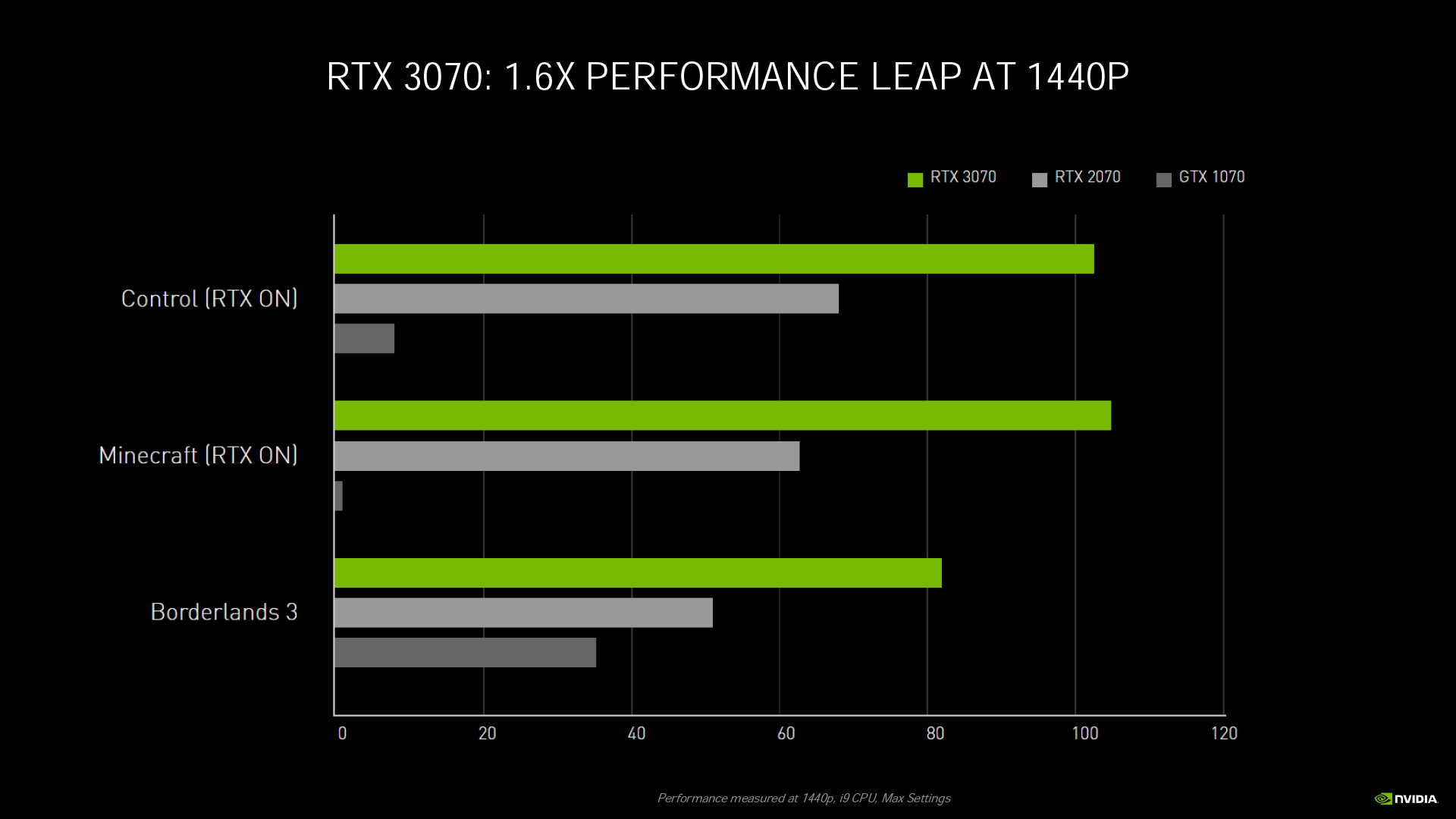
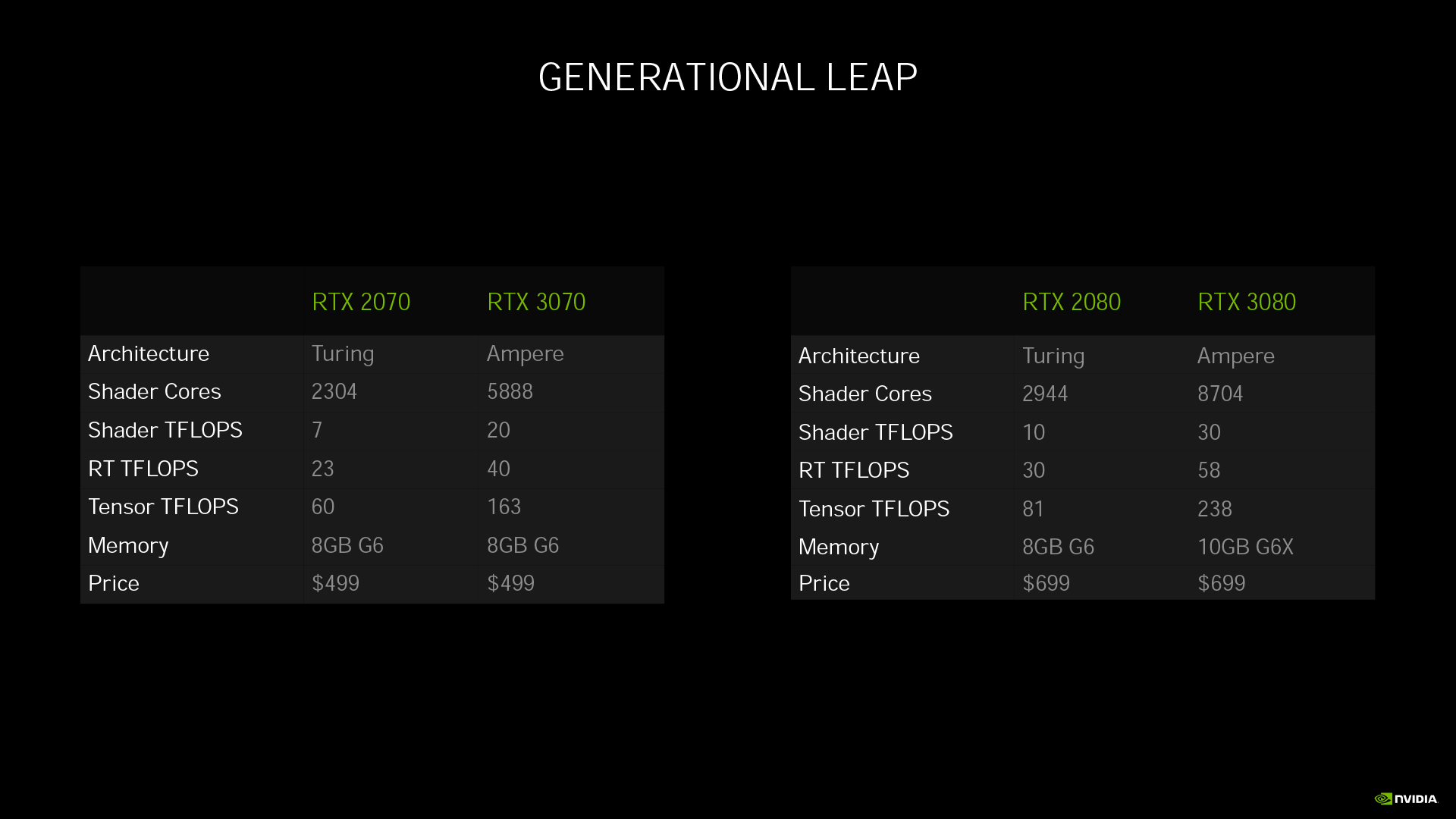
從官方釋出的效能比較圖表來看,不只是 RTX 遊戲,連不支援光線追蹤和 DLSS 的《邊緣禁地3》在 4K 解析度下,RTX 3080 的效能也幾乎能達到 RTX 2080 的 2 倍。而在 WQHD 解析度下,RTX 3070 也能達到 RTX 2070 的 1.6 倍性能。
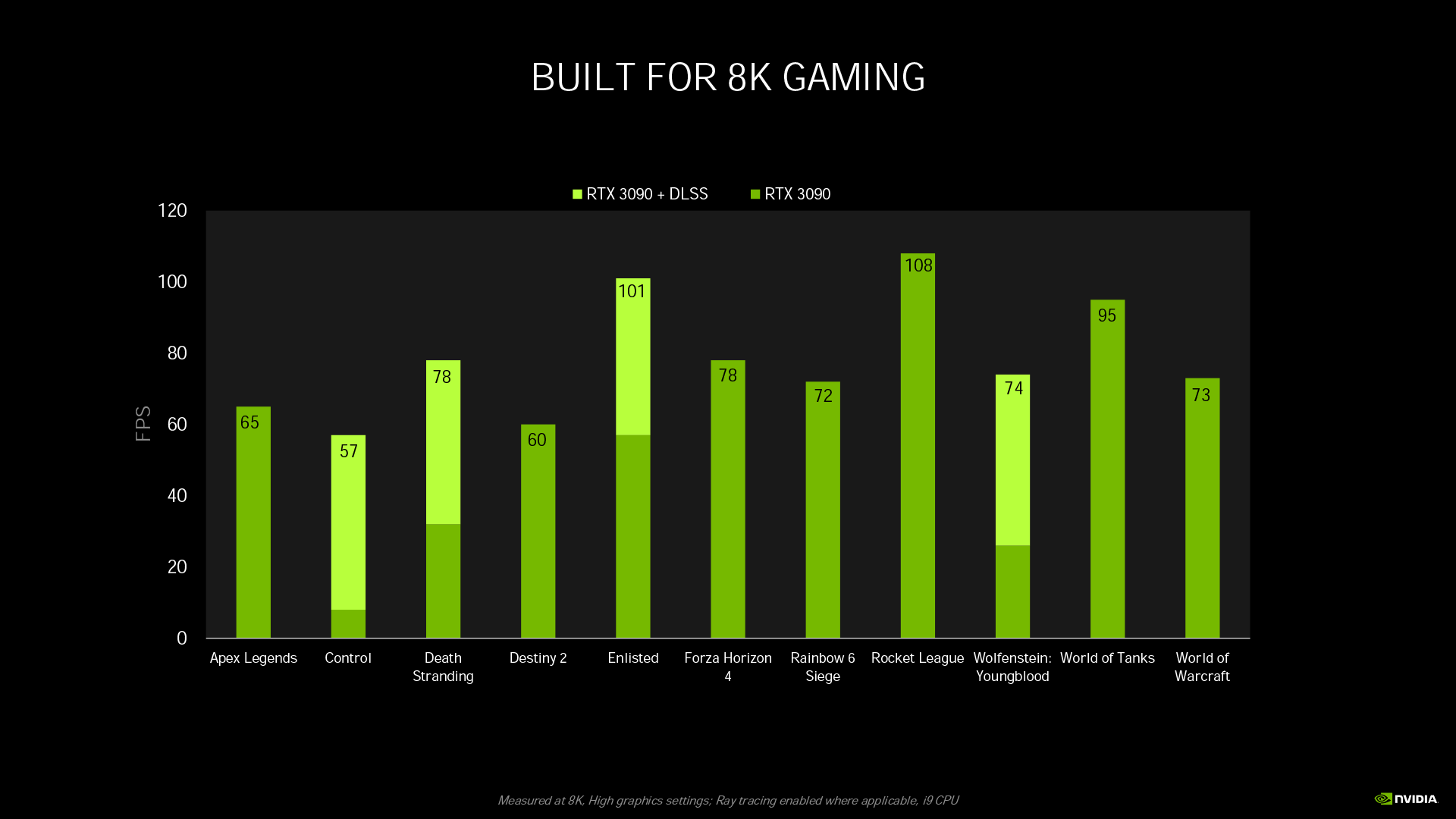

至於這次喊出 8K 這次喊出 8K 60fps 遊戲體驗的 RTX 3090,多款遊戲在高畫質設定下,不需要 DLSS 即可達到 70 fps 以上。而像是《死亡擱淺》、《控制》這類畫面較精細的 AAA 大作,透過 DLSS 直接把玩不動的 8K 解析度變成順暢可玩。
功耗與散熱
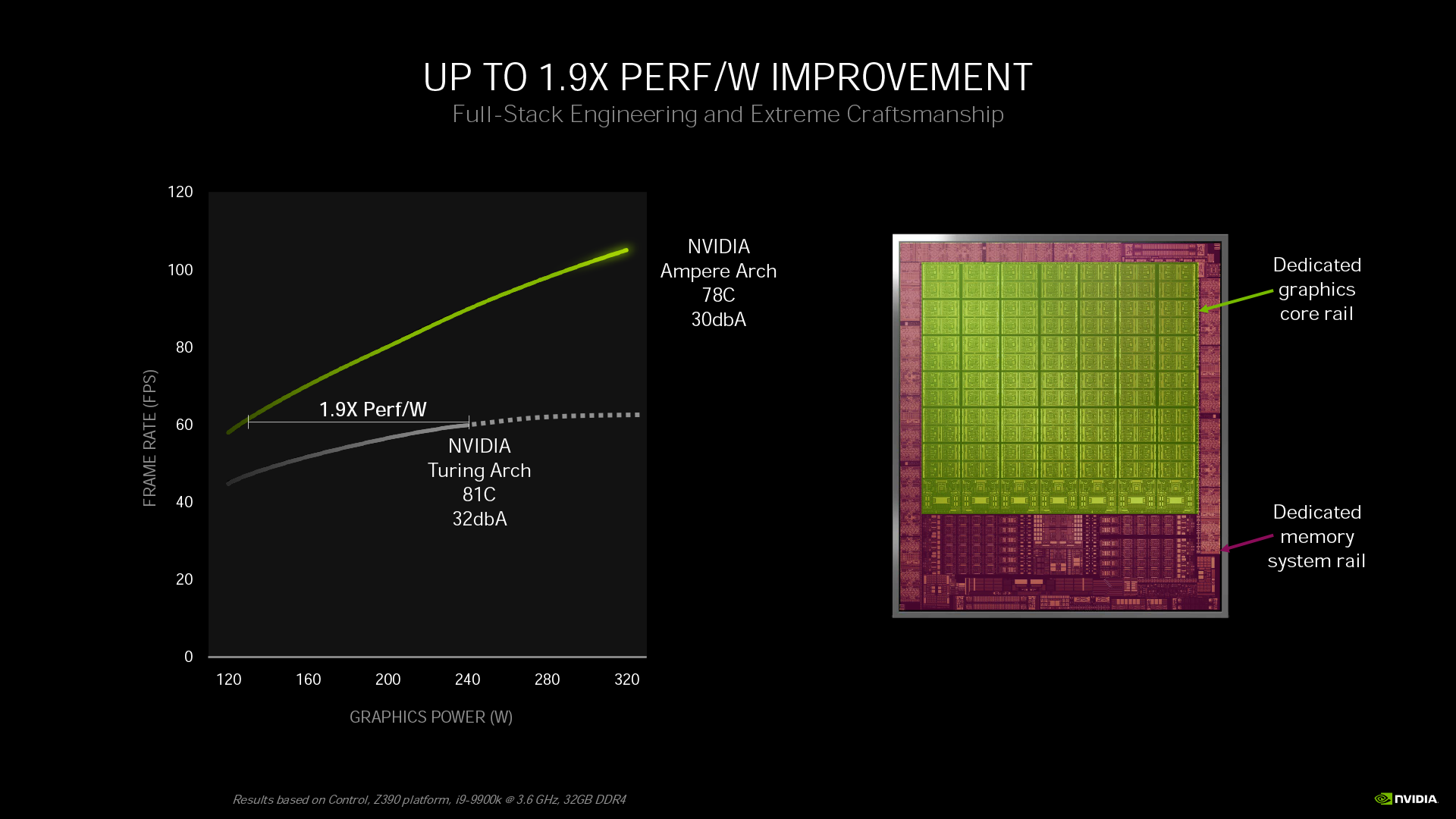
另外一個有趣的部分是功耗,雖然大家都覺得 GeForce RTX 30 系列的 TGP(全卡功耗)相較前代攀升不少,以為電源效率降低了,但其實這反而是 Ampere 架構使用的三星 8nm 製程的優勢。
在相同的效能表現下,GeForce RTX 3080 的能源效率是 RTX 2080 的 1.9 倍。不過 RTX 2080 在公耗大於 240W 後並沒有顯著的效能提升,反而 RTX 3080 一路拉升到 320W 時,效能都穩定隨著功耗攀升而成長。




另一方面,GeForce RTX 30 系列的 Founders Edition 創始版(過去俗稱公版卡)也針對散熱重新設計。這回首次導入正反雙面風扇,讓氣流穿越顯示卡本體後順著熱力加速向上排出,減緩過去氣流因受 PCB 遮擋而堆積在顯卡周遭的問題。
從分解圖片可以看到,GeForce RTX 3080 和 RTX 3090 的 PCB 為了讓出風通道,除了形狀奇異之外尺寸也縮得非常小。要知道在 GPU 需要龐大電力的情況下 PCB 上的元件一定非常多,因此能壓縮到這麼迷你的尺寸確實不容易。NVIDIA 也引進全新立式的 12-pin 電源接頭,節省占用 PCB 面積。
散熱器本體使用均熱板(Vapor Chamber)與 GPU 接觸,再透過熱導管(Heat Pipe)將熱量傳導至鰭片上,搭配正反兩面風扇分別負責不同方向的吹送方式。正面的風扇直接對的顯卡和附近的散熱片吹拂,熱氣會直接往擋板處直接排放至機殼外。背面的風扇則是吸取冷空氣穿越散熱片,再將熱氣向上排出。
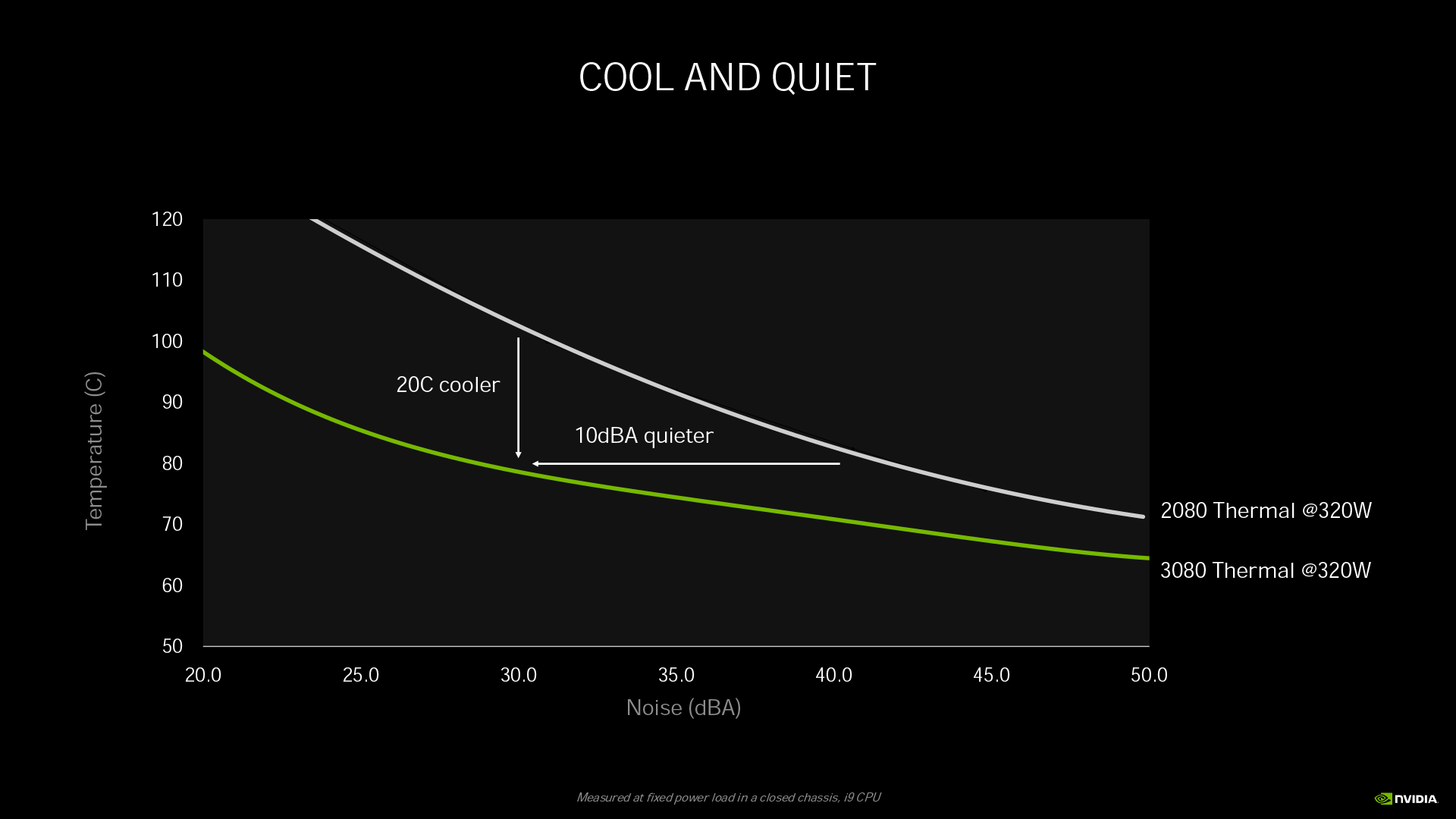
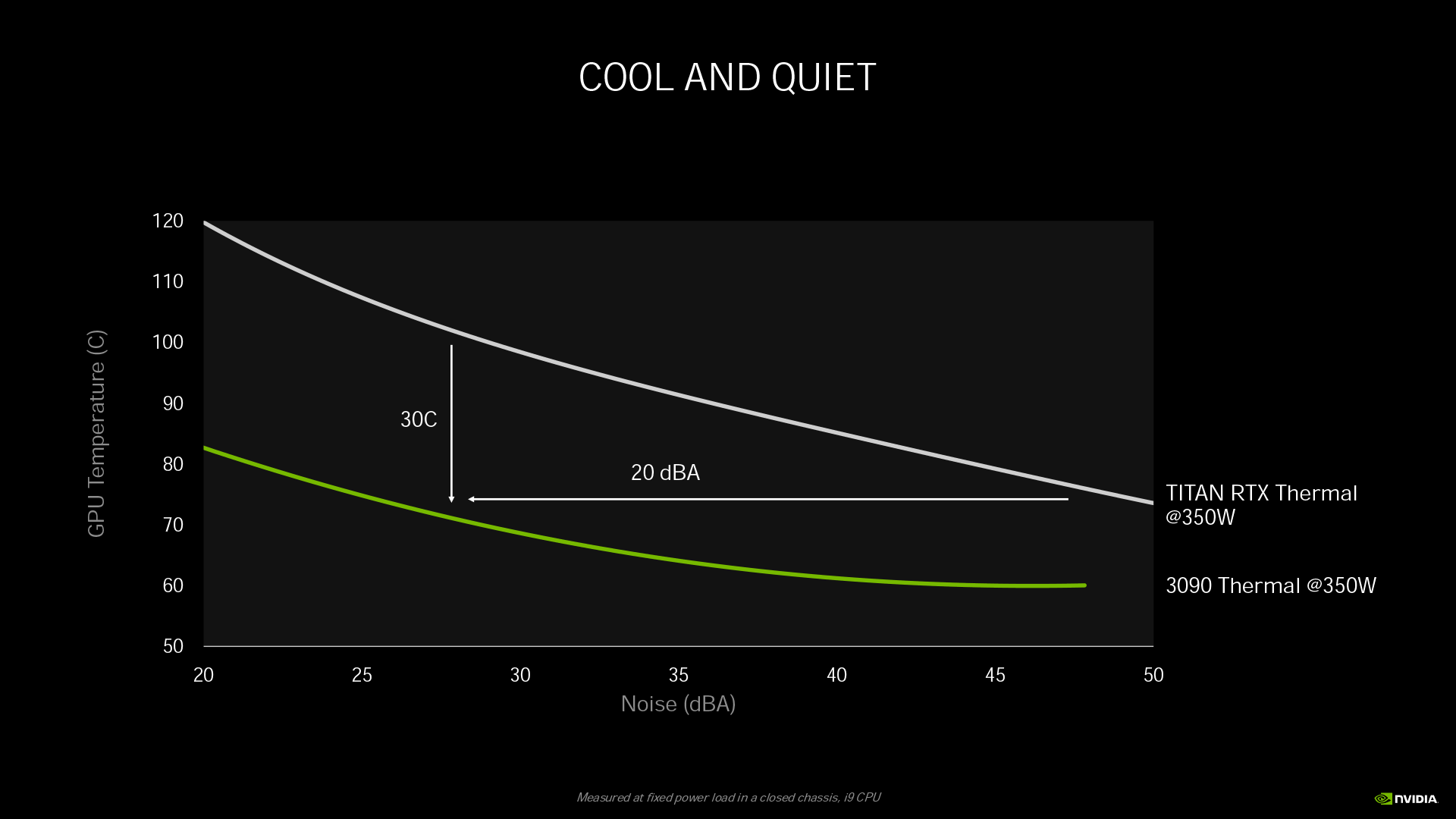
結合功耗狀況與散熱設計後,我們可以看到 Turing 架構的 GeForce RTX 2080 於 TGP 240W 狀態下,溫度為 81°C,此時風扇噪音約在 32dBA。但 Ampere 架構的 GeForce RTX 3080 雖然 TGP 來到 320W,溫度卻可維持在 78°C,風扇噪音值還降到 30dBA。
另外從同樣定於 320W TGP 的噪音與溫度分布曲線圖來看,GeForce RTX 3080 在風扇噪音 30dBA 時溫度比 RTX 2080 低了 20°C,而溫度為 78°C 時風扇噪音比 RTX 2080 少了 10dBA。總和來看雖然 RTX 3080 功耗提升,但溫度表現反而比 RTX 2080 還優異。
RTX IO
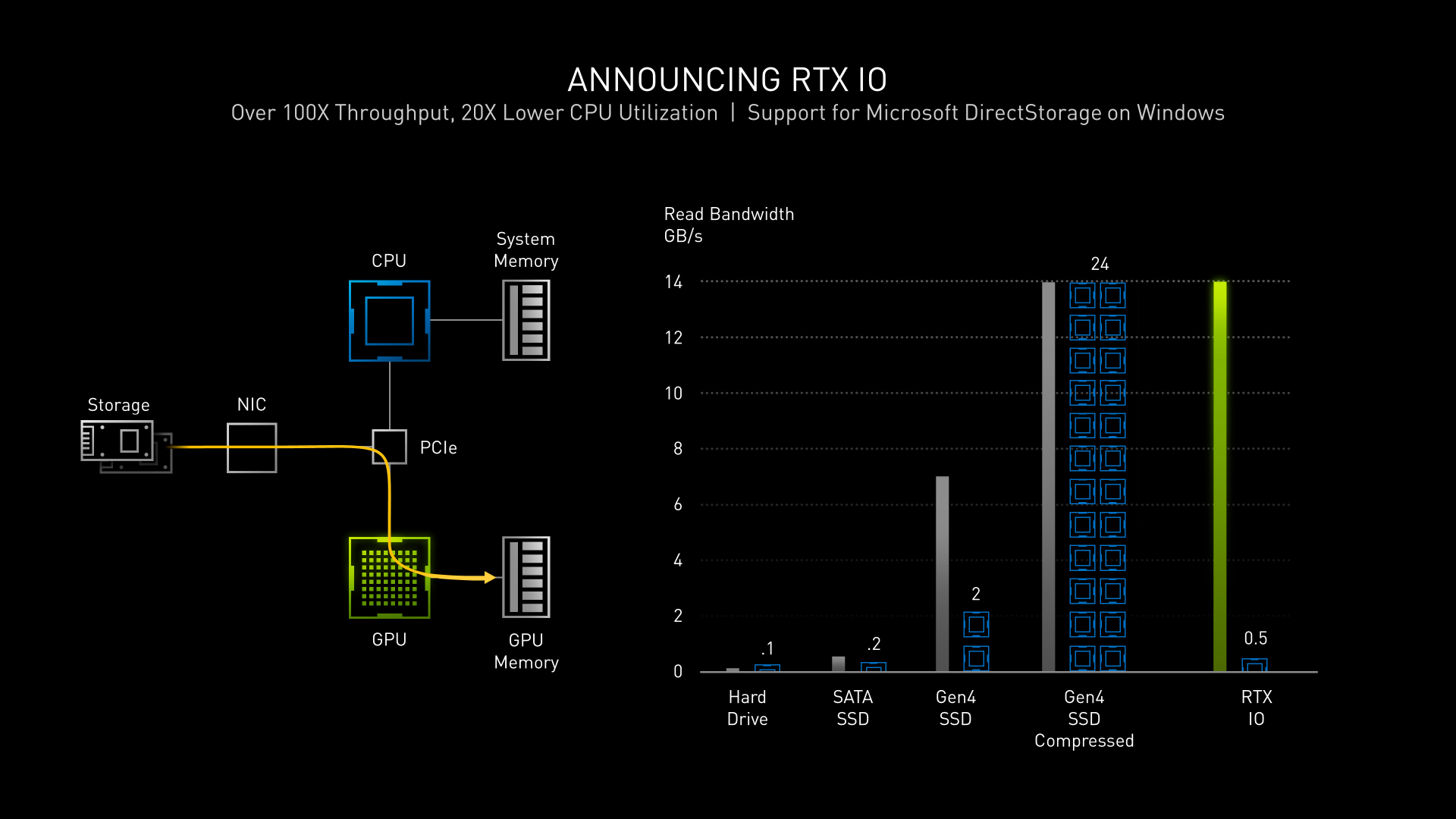
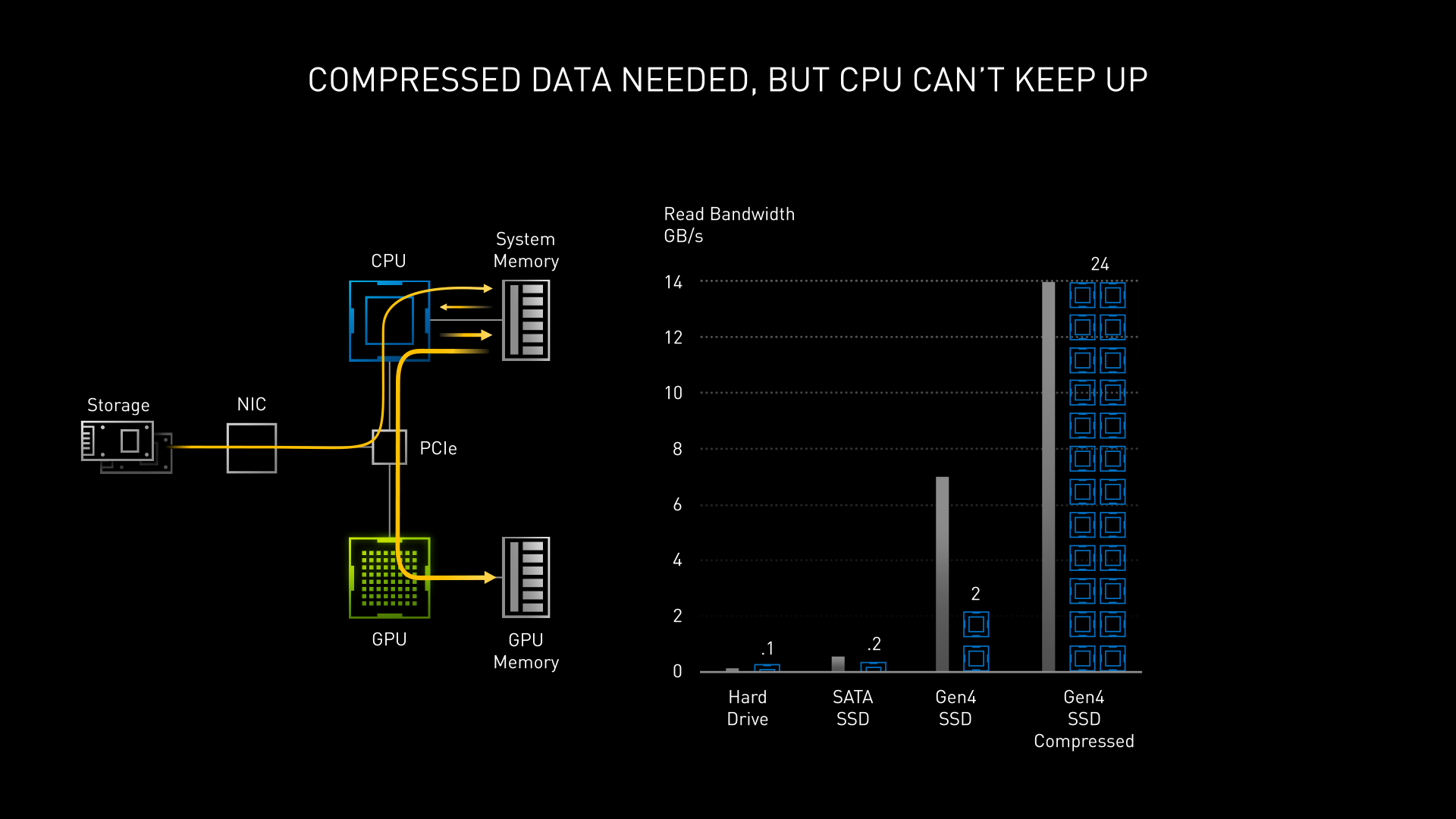
隨著遊戲畫面與物件精細度提高,資料量當然也水漲船高,如今一套 AAA 大作級遊戲的數據量幾乎可以上看 200GB,真的非常占用儲存空間,因此不少遊戲資料都使用壓縮方式減少儲存體積。
然而當需要運行遊戲時,勢必得將這些資料解壓縮出來。傳統上必須透過 CPU 運算並將其先暫存置系統記憶體後,再回傳 CPU 轉傳至 GPU,這種作法實在曠日費時又佔用 CPU 資源。
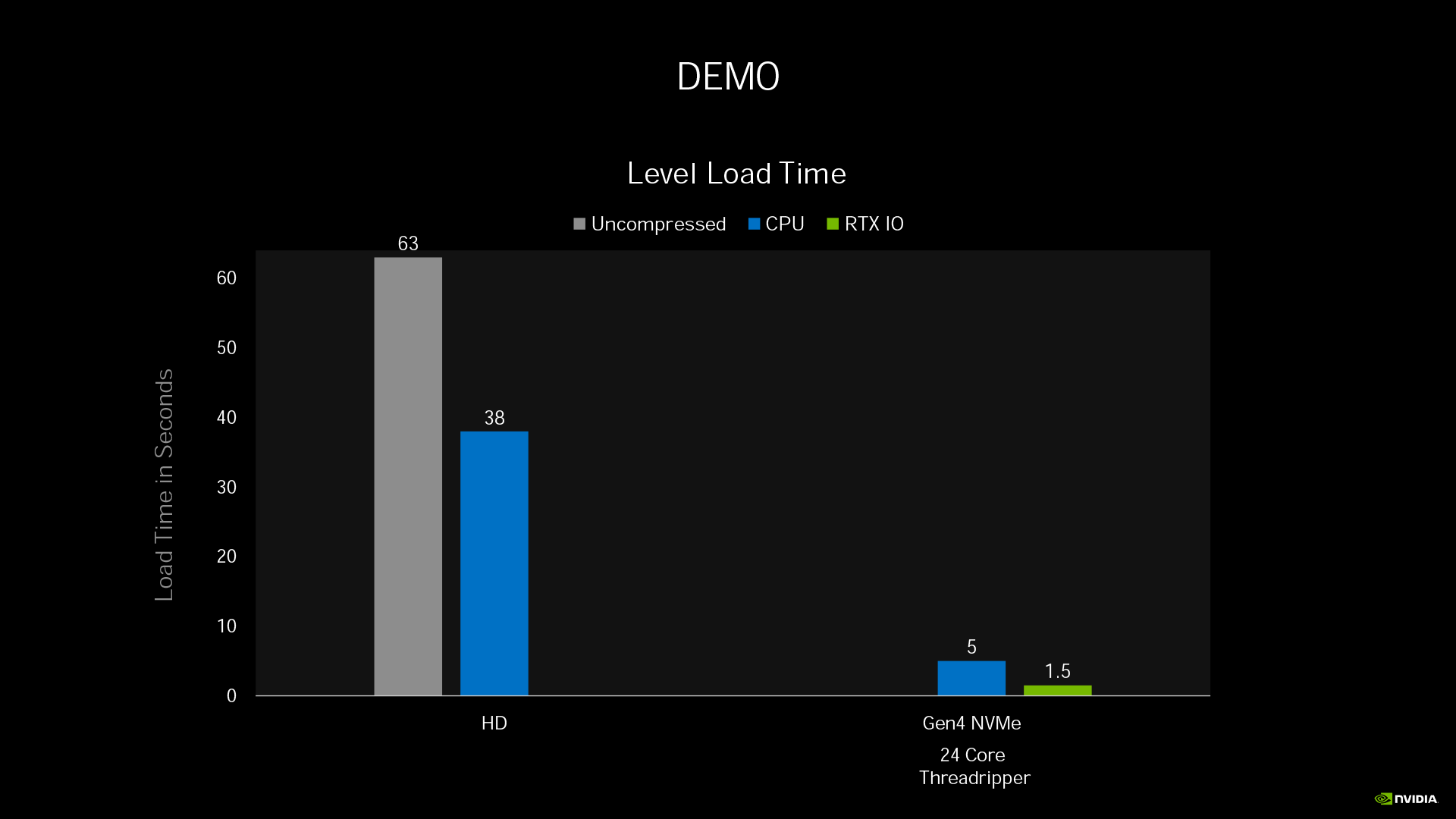
因此 NVIDIA 與微軟合作,運用 DirectStorage API,讓 NVMe SSD 內的資料直接從 PCIe 4.0 通道輸送至 GPU 進行解壓縮,並存放顯卡記憶體等待取用。由於 GPU 的平行運算優勢非常適合解壓縮運算,所以除了減少 CPU 負擔之外,還能大幅縮短解壓縮所需時間,讓遊戲載入更有效率。
總結
綜合以上資料,NVIDIA Ampere 架構不只強化光線追蹤和 Tensor 運算,連傳統著色渲染效能都大幅提升到全新水平,再加上精湛的 PCB 規劃與嶄新的雙面風扇排熱設計,確實讓人感受到效能大躍進。不過實測數據仍受 NDA 約束,請靜待台灣時間 9 月 14 日 21:00 解禁。





![最瘋狂的果汁第一次登陸日本! [怪物芒果洛科] 發佈決定 ! 活動,你可以得到領先一步也執行!](https://i0.wp.com/saiganak.com/wp-content/uploads/2022/02/monster-energy-mango-loco-release-00.jpg?resize=266,160)